
Building, Breaking, and Rebuilding: My Journey to a Smarter RAG Application
Ever tried organising years of accumulated knowledge into a searchable system? That's what led me down the rabbit hole of RAG (Retrieval-Augmented Generation). What started as a simple project to organise research notes turned into a master class in building robust AI systems. Here's what I learned.
The Journey Begins: A Simple but Flawed Start
Picture this: You have a vast collection of research notes, code snippets, and technical documentation. Your first instinct? Build something simple:

This basic pipeline worked... until it didn't. The prompts were as simple as the architecture:

Here's where things got interesting:
The First Cracks Appear: When Reality Hits Your RAG
🔍 Problem 1: The Backend-itis
Imagine going to a library where 90% of the books are about JavaScript, and you're trying to find information about Python. That's what happened with my corpus imbalance. Ask about frontend development, and my system would respond, "Have you considered implementing this in Node.js?" No, system, that's not what I asked!
The static prompts made this worse - they had no awareness of the content domain or query intent. It was like having a biased librarian who spent their entire career in the backend section and now recommends "Design Patterns" for everything, including your CSS questions.
⏱️ Problem 2: The Recency Syndrome
You know how your social media feed always shows the latest posts first? My RAG system had the same addiction to novelty. The prompts weren't helping either - they treated all information as equally relevant regardless of its age or context. Ask about a coding pattern I documented in 2020, and it would instead tell me about a similar (but less relevant) snippet I wrote last week.
📦 Problem 3: The Token Buffet
Picture yourself at an all-you-can-eat buffet, but your plate has a strict size limit. That was my LLM, trying to digest chunks of text that were way too big, with prompts that didn't guide proper information synthesis. I was essentially asking it to eat a whole turkey in one bite.
The Metadata Revolution: Making Our Vectors and Prompts Smarter
Remember those old library cards that told you not just the book's title, but also its location, subject, and checkout history? That's what good chunk metadata does for your RAG system. But metadata alone isn't enough - your prompts need to know how to use it effectively:
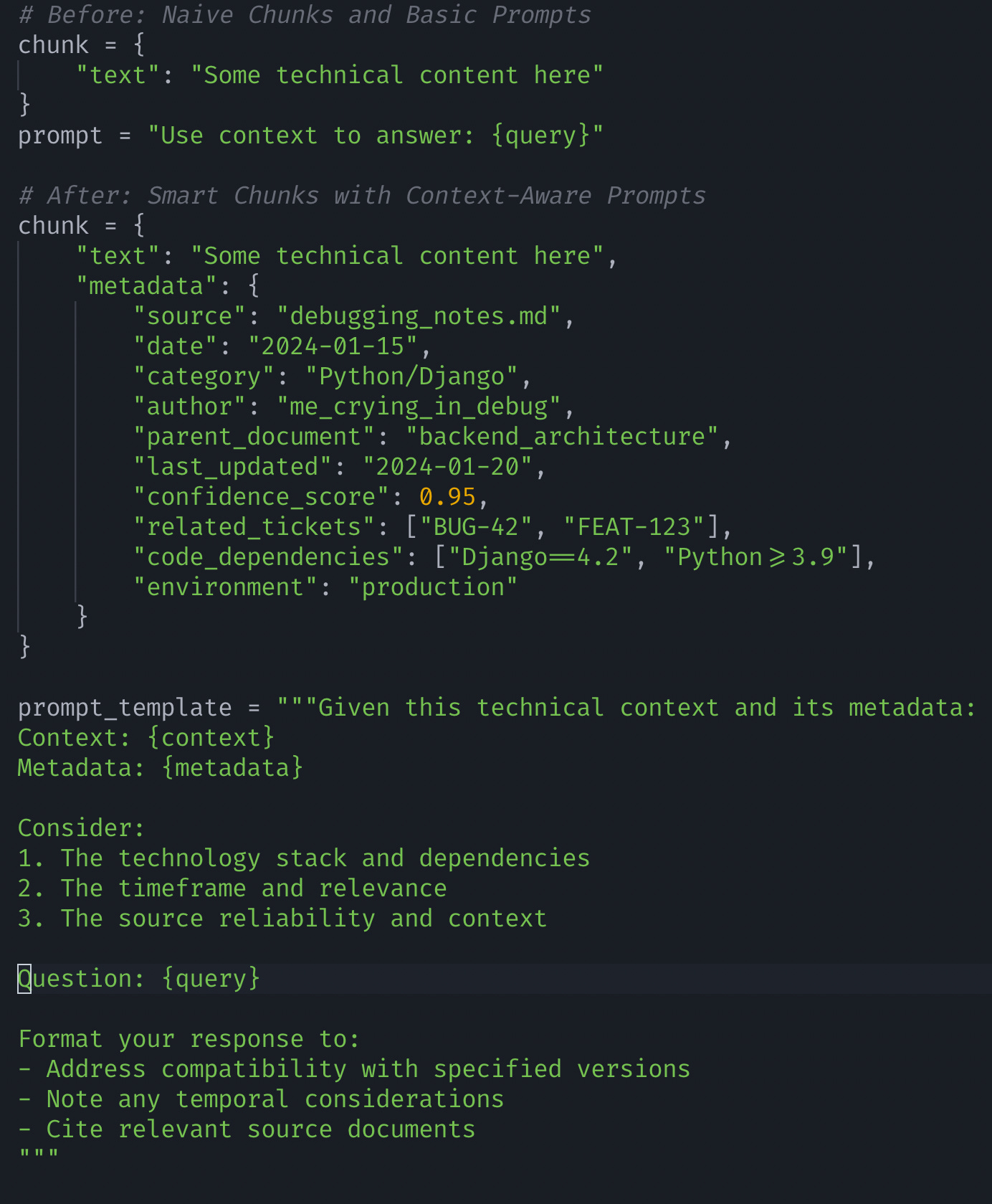
Think of metadata as your chunk's LinkedIn profile - it's not just about what they know, but their entire professional history. This rich context, combined with smarter prompts, helps your RAG system make better decisions.
Taking It Up a Notch: The Second Iteration
Learning from these failures, the second version introduced some key improvements:


Better? Yes. Perfect? Not quite. New challenges emerged:
Information synthesis across documents remained problematic
Source tracing was nearly impossible
The system couldn't recognise when it was out of its depth
The Final Form: Building a Robust RAG System
The final version transformed into a sophisticated knowledge engine with advanced prompt chaining:

Key Innovations
Hierarchical Document Processing with Intent Recognition

Smart Retrieval with Guided Synthesis

Self-Reflecting Quality Control
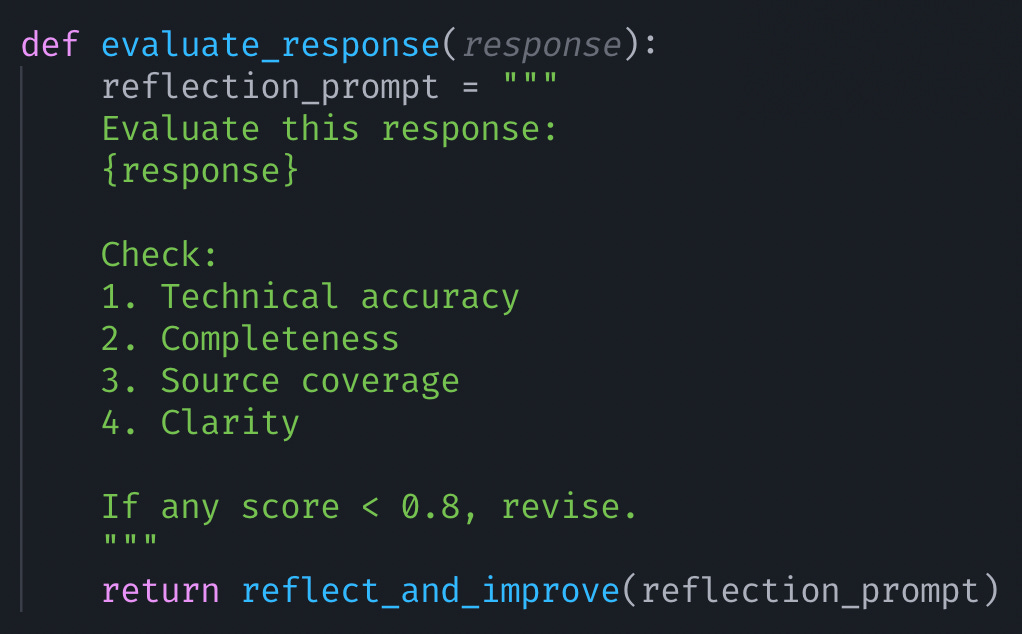
The Bigger Picture: What This Journey Taught Me
Building a RAG system isn't just about connecting components—it's about understanding how information flows through your system and crafting prompts that guide this flow effectively. Here's what I learned:
Critical Success Factors: The Secret Sauce
🎯 The Art of Chunk-Fu and Prompt Engineering
Document preprocessing isn't just splitting text - it's like being a master chef preparing ingredients. Your prompts are the recipes that determine how these ingredients come together. Each type of document needs its own handling strategy and corresponding prompt template.
🏷️ Metadata: The Superhero Origin Story
Every chunk of text needs its origin story - where it came from, what it does, who its friends are. Your prompts need to know how to read these stories and use them to craft better responses.
🎭 The Multi-Stage Talent Show
Single-stage retrieval with basic prompts is like picking a movie based only on its title. Multi-stage retrieval with prompt chaining is like having a conversation with a film critic who considers the plot, reviews, AND historical context.
⚖️ The Uncertainty Principle of RAG
Sometimes the most intelligent answer is "I'm not quite sure about this." Build your system's prompts to embrace uncertainty and provide clear confidence metrics. Your users will thank you!
On Using Frameworks
Could established frameworks like LlamaIndex have saved time? Absolutely. But building from scratch taught me invaluable lessons about:
System architecture trade-offs
Prompt engineering strategies
Failure modes and their solutions
Performance optimisation opportunities
For production systems, evaluate existing frameworks. For learning? Build it yourself. The insights are worth the effort.
Looking Ahead
RAG systems are becoming central to how we interact with large knowledge bases. Whether you're building one from scratch or using existing frameworks, understanding these core concepts - from chunking strategies to prompt engineering - will help you build more reliable, transparent, and useful systems.
Remember: The goal isn't just to connect an LLM to a database—it's to build a system that reliably augments human knowledge while being honest about its limitations. Your prompts are the key to achieving this balance.
What challenges have you faced while building RAG systems? I'd love to hear about your experiences in the comments below.