


The Art of Sampling: Controlling Randomness in LLMs
A Mental Model for Temperature, Top-k, and Top-p
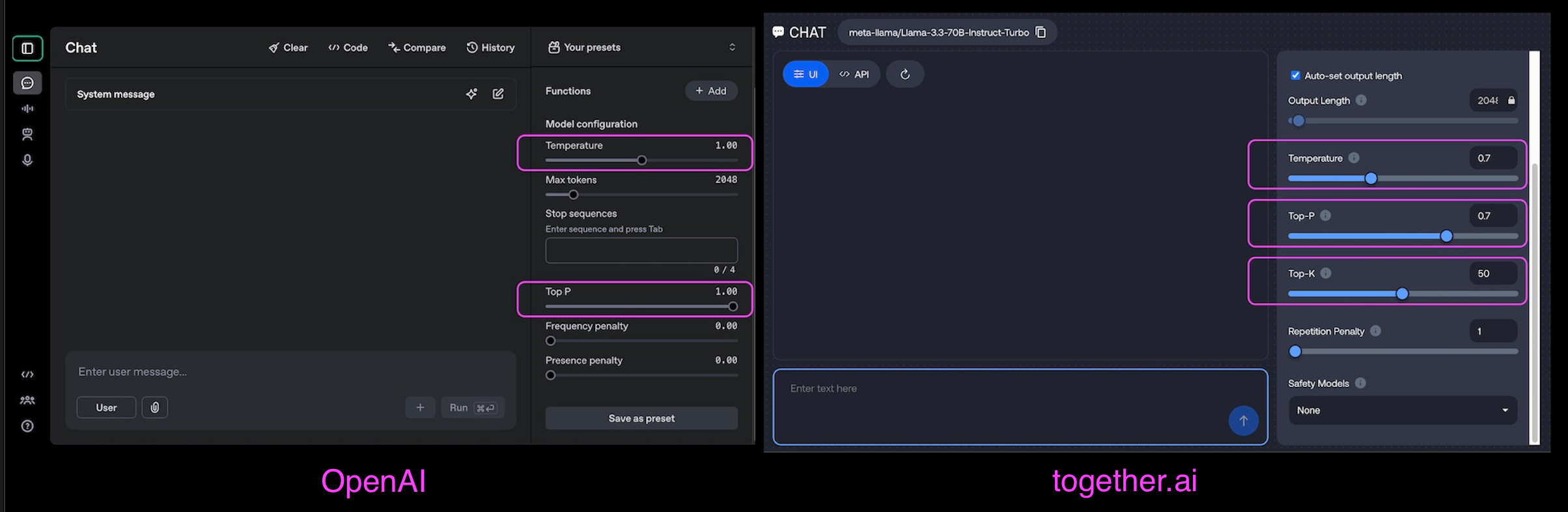
If you’ve ever tweaked an LLM’s output to make it more creative, factual, or balanced, you’ve likely encountered temperature, top-k, and top-p. These are the hidden dials that shape how the LLM responds, whether it’s rigidly precise, wildly imaginative, or somewhere in between. Let’s break them down with a mental model you won’t forget.
Why Should You Care?
Sampling introduces randomness into LLM outputs, making them unpredictable or as AI researchers call it : 'non-deterministic.' Understanding how these variables influence model behavior is crucial, as they can lead to undesirable effects such as hallucinations, inconsistency, and unpredictability. By mastering temperature, top-k, and top-p, you can strike a balance between creativity and reliability, whether you're building a medical chatbot or a fantasy story generator.
Fundamentals of Token Selection
An LLM predicts the probability of the next token (a word, subword, or character) in a sequence. The simplest approach, greedy sampling, always selects the most likely1 token, which works well for classification tasks but often leads to repetitive, predictable language generation for language models. Instead, modern LLMs use sampling strategies that introduce controlled variability by selecting tokens based on their probabilities.
How does a model compute these probabilities? The model outputs logits2 (raw scores) for each token in its vocabulary. These logits are then transformed into probabilities via the softmax function:
Each sampling strategy modifies these probabilities in different ways before selecting the next token.
Now that we understand what sampling is, let’s explore the three key dials.
Temperature: The Creativity Thermostat
Temperature cranks up the creative heat! A higher temperature shakes things up, giving less common words a fighting chance, while a lower temperature keeps things steady and reliable.
Under the hood Temperature scales (by a factor of 1/T) the logits before applying softmax:
The higher the temperature, the more evenly spread the probabilities, leading to more varied outputs. The lower it is, the more confident and deterministic the model becomes.
High temperature (T > 1): Flattens the probability distribution, giving unlikely tokens a better chance. Think of this as turning your AI into a whimsical poet.
Low temperature (T < 1): Sharpens the distribution, favoring high-probability tokens. Your AI becomes a cautious accountant.
Temperature = 0: A special case—forces the model to always pick the most likely token (greedy decoding). Outputs are deterministic but risk repetition.
Imagine an AI chef crafting a recipe:
T = 03: The chef only uses the most obvious ingredient (e.g., "salt"). Safe but boring.
T = 0.7: The chef adds a pinch of unexpected spices (e.g., "saffron"). Balanced and tasty.
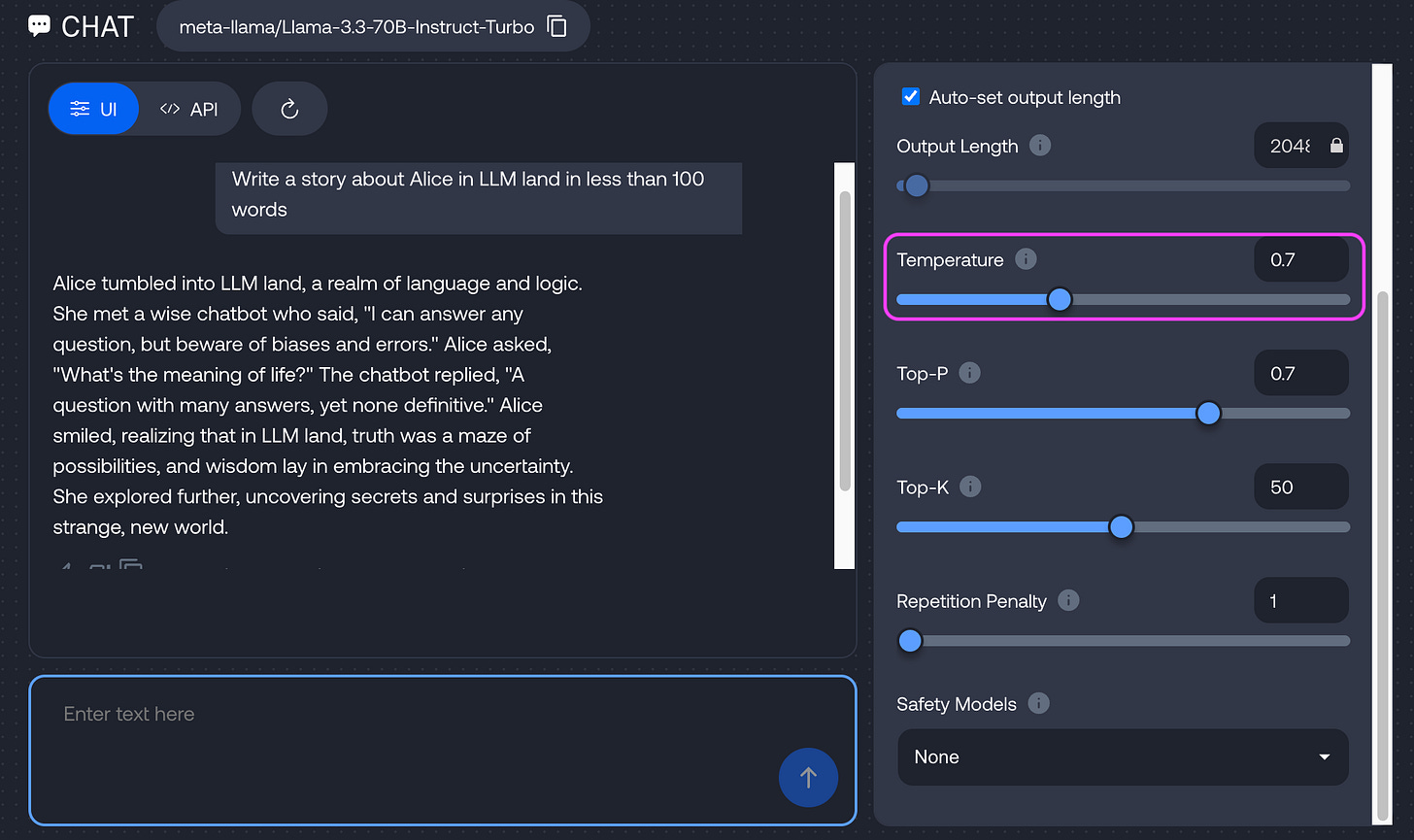
T = 0.7 T = 1.5: The chef tosses in jackfruit, chili powder, and maple syrup—because why not?
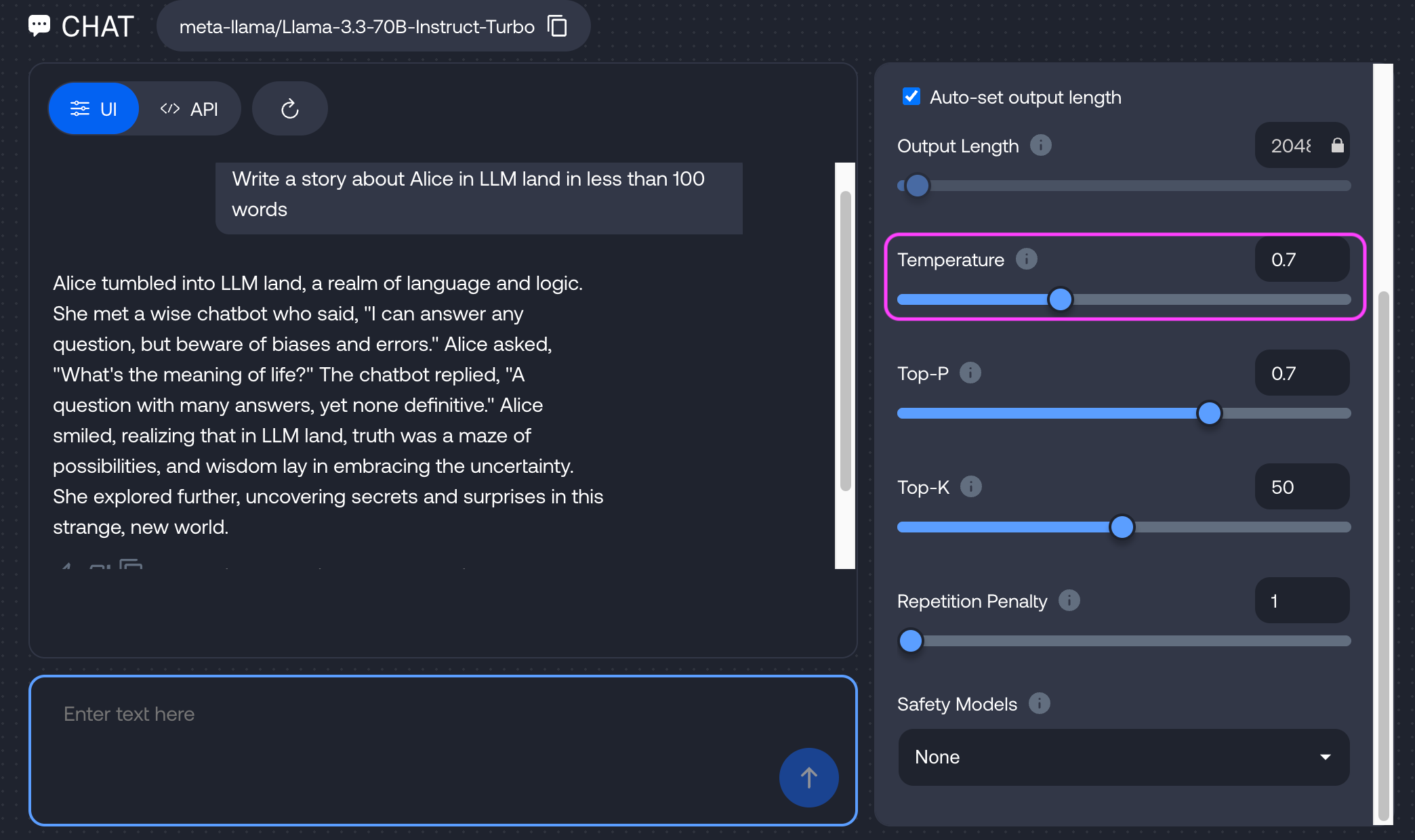
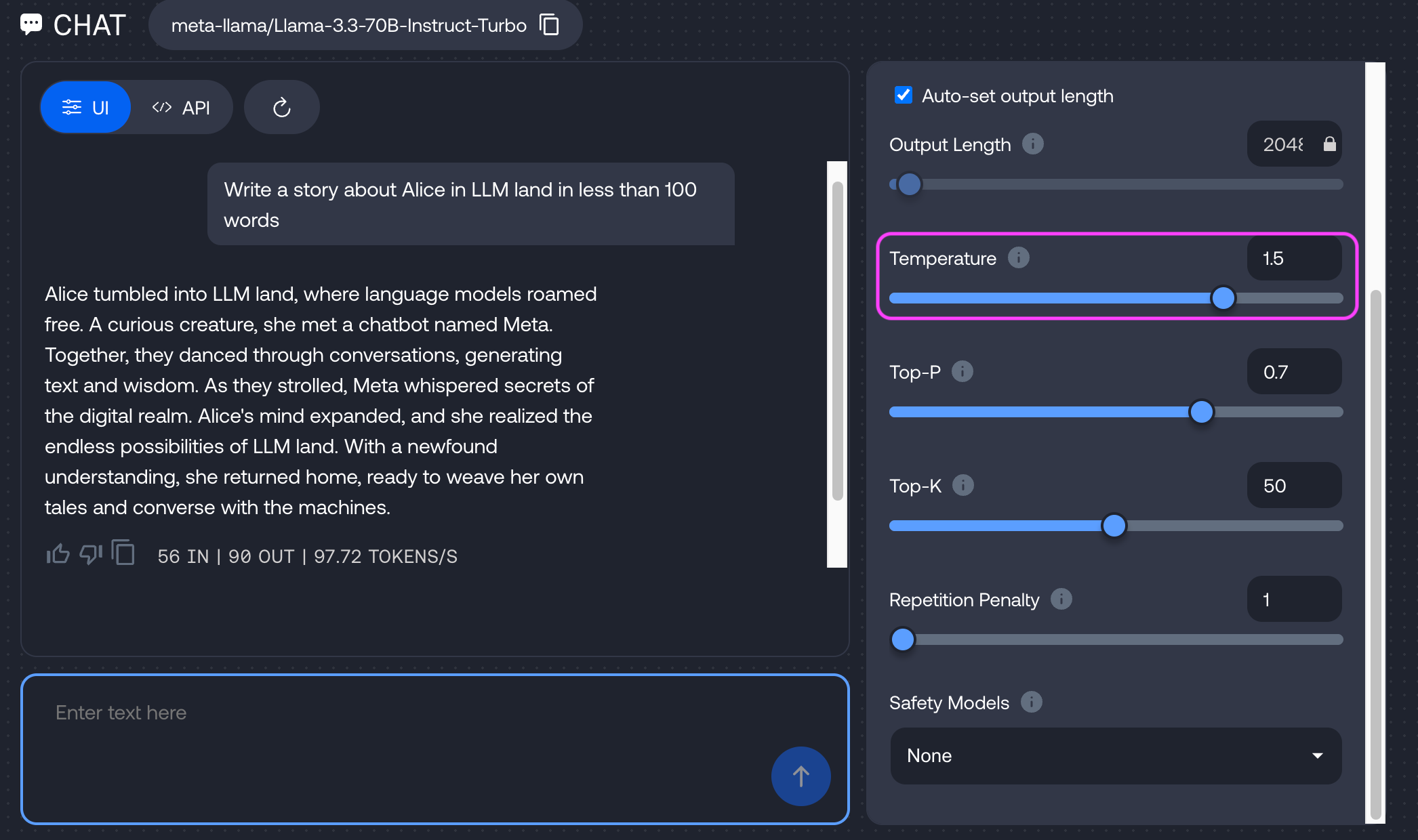
When to use it
T = 0: Debugging, factual QA, or code generation.
T = 0.5–0.9: Most conversational tasks (e.g., chatbots).
T ≥ 1.0: Brainstorming or experimental writing.
Top-k: The Shortlist Selector
Top-k helps reduce computation without sacrificing the diversity of the model’s response. Instead of evaluating every possible word in the models vocabulary, the model focuses only on the k most probable options, significantly speeding up processing. After selecting these top-k candidates, softmax is applied to generate probabilities.
Low k (e.g., 10): Conservative, predictable outputs.
High k (e.g., 100): Diverse but potentially incoherent.
Continuing with our chef analogy, let’s say the chef has 100 possible ingredients to choose from, but we don’t want them considering all of them. That’s where top-k comes in.
Top-k = 1 → The chef always picks the most probable ingredient (boring but safe).
Top-k = 10 → The chef picks from the top 10 most likely ingredients, adding diversity.
Top-k = 50+ → The chef considers a much broader range, leading to more surprising results.
When to use it
Use small k for tasks requiring strict focus (e.g., legal documents).
Larger k works for creative writing or marketing copy.
Top-p (Nucleus Sampling): The Adaptive Filter
While Top-k picks a fixed number of options, Top-p (nucleus sampling) is more flexible, it adjusts dynamically based on context.
Top-p works by summing probabilities of the most likely words until a threshold (p) is met. For example, with top-p = 0.9, the model considers the fewest words that collectively hold 90% probability giving flexibility while keeping things relevant. The higher the top-p value, the wider the selection pool, adding more variety.
It’s like stopping at just the right number of ingredients when cooking; enough for balance, but not so many that things get chaotic. 🍲🎶
Imagine the chef stops adding ingredients once the chosen ones make up a significant portion of the recipe (say, 90%).
Top-p = 0.9 → The LLM picks from the smallest set of words that collectively hold 90% probability.
Top-p = 0.99 → More variety, but still somewhat controlled.
Top-p = 1.0 → Equivalent to pure random sampling.
The advantage? Top-p adjusts dynamically; sometimes considering just a few options (when certainty is high) and other times considering many (when more diversity is needed). It’s a more context-aware way to control randomness.
📌 Frequency & Presence Penalty
While temperature, top-k, and top-p control randomness, two additional parameters refine repetition and novelty:
Frequency Penalty:
Reduces the likelihood of tokens that have already appeared frequently in the generated text.
📌 Higher values → Less repetition (great for avoiding redundant phrases like "In conclusion… In conclusion…").
📌 Lower values → Allows natural repetition (useful for poetic refrains or technical terms).
Presence Penalty:
Penalizes tokens that have appeared at all in the generated text, encouraging the model to introduce new topics or vocabulary.
📌 Higher values → More novel concepts and word choices (good for brainstorming or exploratory writing).
📌 Lower values → Stays tightly focused on the existing context (ideal for QA or summaries).
🎯 Pro Tip:
If you are seeing repeat phrases in the output, increase frequency penalty.
If outputs feel stale or lack new ideas (e.g., "This can… This can.…"), boost presence penalty.
⚠️ Overusing these penalties can lead to incoherent or nonsensical outputs!
How to Choose the Right Settings?
Factual & Consistent Output → Temperature = 0, Top-k = 1 (greedy), Top-p = 0.9
Balanced Creativity & Coherence → Temperature = 0.7, Top-k = 40, Top-p = 0.9
Maximum Creativity & Exploration → Temperature = 1.2, Top-k = 100, Top-p = 0.95
📌 Quick Cheat Sheet4
Need facts? →
T=0, Top-k=1, Top-p=0.9Casual chatbot? →
T=0.7, Top-k=40, Top-p=0.9Wild creativity? →
T=1.2, Top-k=100, Top-p=0.95
For most applications, Temperature = 0.7 & Top-p = 0.9 strike the best balance between creativity and coherence.
Pro Tips
✅ Don’t combine top-k and top-p: They can conflict (e.g., top-k=50 + top-p=0.9 might exclude high-probability tokens).
✅ Start with temperature=0.7 + top-p=0.9: This works for 80% of use cases.
✅ Repetition? Lower temperature or tweak top-p.
Final Takeaway: The LLM Kitchen
Temperature: How “spicy” the AI’s choices are.
Top-k: How big the ingredient shortlist is.
Top-p: How much of the recipe must be covered.
By tweaking these dials, you shape the LLMs personality, from meticulous engineer to free-spirited artist. Next time your model feels too boring or unhinged, remember: you’re the chef in this kitchen.
Now that you know how to control the LLMs personality, what’s your perfect mix?
Try it out and share your most unexpected AI-generated response below!
one with the highest probability
Each logit corresponds to one token in the model’s vocabulary; logits don’t represent probabilities, and they don’t sum up to one. That’s why they are passed to the Softmax function
Temperature can't be 0 since logits can't be divided by zero; instead, the model selects the highest logit token without adjusting logits or applying softmax.
YMMV! Test these settings before you deploy to production
Thank you for sharing.