pgvector doesn't scale
It’s funny how engineers (myself included) assume that if you can store vectors in Postgres, you should. The logic

Things I've learned or things I find interesting will be logged here. For long-form content, you might want to check out my newsletter.



If you want to actually understand transformers, this guide nails it. I've read a bunch of explanations and this one finally made the pieces fit together.
The thing that works is it doesn't just throw the architecture at you. It shows you the whole messy history first. RNNs couldn't remember long sequences. LSTMs tried to fix that but got painfully slow. CNNs were faster but couldn't hold context. Then Google Brain basically said "screw it, let's bin recurrence completely and just use attention." That's how we got the famous paper. Once you see that chain of failures and fixes, transformers stop being this weird abstract thing. You get why masked attention exists, why residual connections matter, why positional encodings had to be added. It all clicks because you see what problem each bit solves.
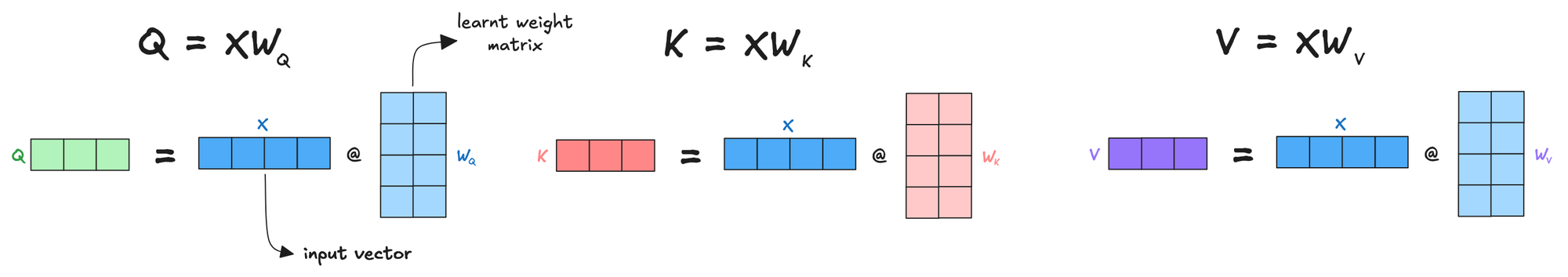
The hand-drawn illustrations help too. There's a Google search analogy for queries, keys, and values that made way more sense than the maths notation ever did. And the water pressure metaphor for residual connections actually stuck with me. It took the author months to research and draw everything. You can tell because it doesn't feel rushed or surface-level. If you've been putting this off because most explanations either skim over details or drown you in equations, this one gets the balance right.
https://www.krupadave.com/articles/everything-about-transformers?x=v3

Most engineers read research papers like blog posts, expecting instant clarity. That’s why so many give up halfway through. The trick isn’t to read harder but to read differently. This https://blog.codingconfessions.com/p/a-software-engineers-guide-to-reading-papers reframes paper reading as a process you can iterate on, not a one-shot test of intelligence.
The author suggests a multi-pass approach. First, skim the abstract, intro, results and conclusion to see if the paper is even relevant. Next, read the body while flagging any gaps in your understanding. Finally, revisit it with fresh context and ask why each step exists. The shift is subtle but powerful: instead of fighting the paper, you collaborate with it.
What I’m taking away is this. Reading research is a skill, not a talent. If I approach papers as layered workflows rather than puzzles to solve in one go, I’ll extract more ideas I can actually build on.
Original article: https://blog.codingconfessions.com/p/a-software-engineers-guide-to-reading-papers

Some LLMs lean left. Others lean right. The Anomify study shows that mainstream models are not neutral arbiters of truth, they come with their own built-in world-views. That means the answer you get is shaped not only by your prompt, but by the ideological fingerprint of the model you chose in the first place.
I assumed most models would at least converge on a kind of centrist neutrality, but the experiment revealed clear and consistent patterns in how they respond to social and political questions. One model might advocate for stronger regulation while another leans libertarian. Some avoid topics entirely while others dive in. This matters because it is easy to treat LLM output as objective when it is really a reflection of training data, guardrails, and product philosophy.
The takeaway is simple. If you are using an LLM for reasoning or advice, the choice of model is a design decision, not a cosmetic one. You are not only choosing a capability profile. You are inheriting a point of view.
Link to study: https://anomify.ai/resources/articles/llm-bias
It turns out that when we ask reasoning capable models such as the latest LLMs (GPT-5 family, Claude Opus and successors, Gemini 1.5 Pro etc.) to think through problems, they often behave like explorers wandering aimlessly rather than systematic searchers. The paper titled Reasoning LLMs are Wandering Solution Explorers formalises what it means to systematically probe a solution space (valid transitions, reaching a goal, no wasted states), but then shows that these models frequently deviate by skipping necessary states, revisiting old ones, hallucinating conclusions or making invalid transitions. This approach can still look effective on simple tasks, but once the solution space grows in depth or complexity, the weaknesses surface. Therefore the authors argue that large models are often wandering rather than reasoning, but their mistakes stay hidden on shallow problems.
The upshot is that a wanderer can stumble into answers on small search spaces, but that same behaviour collapses when the task becomes deep or requires strict structure. The authors show mathematically and empirically that shallow success can disguise systemic flaws, but deeper problems expose the lack of disciplined search. Therefore performance plateaus for complex reasoning cannot simply be fixed by adding more tokens or more compute, but instead require changes in how we guide or constrain the reasoning process.
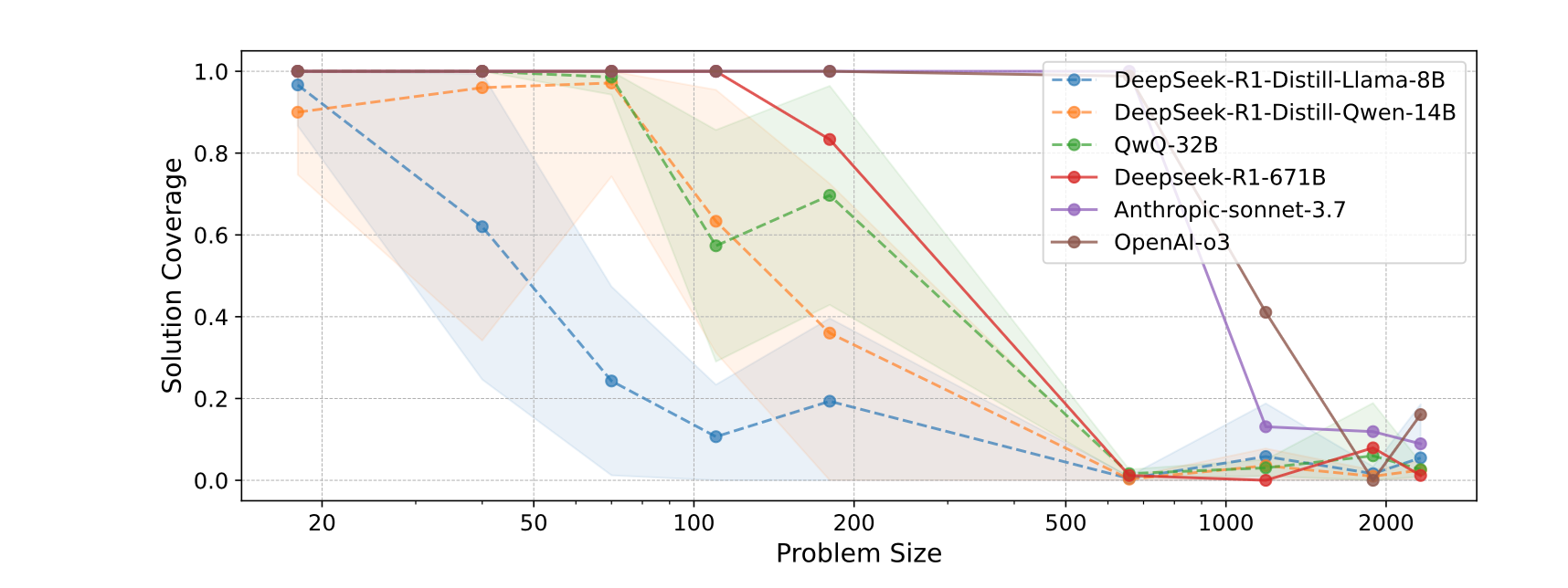
For us as AI engineers, this is useful because it reinforces a shift from evaluating only outcomes to evaluating the path the model took to get there. A model that reasons by wandering might appear competent, but it becomes unreliable in real systems that require correctness, traceability and depth. Therefore we may need new training signals, architectural biases or process based evaluation to build agentic systems we can trust. In other words, good reasoning agents need maps, not just bigger backpacks.
Worth a quick scan 👉 https://arxiv.org/abs/2505.20296v1

There's this technique called representation engineering that lets you modify how AI models behave in a surprisingly effective way. Instead of carefully crafting prompts or retraining the model, you create “control vectors” that directly modify the model’s internal activations. The idea is simple: feed the model contrasting examples, like “act extremely happy” versus “act extremely sad,” capture the difference in how its neurons fire, and then add or subtract that difference during inference. The author shared some wild experiments, including an “acid trip” vector that made Mistral talk about kaleidoscopes and trippy patterns, a “lazy” vector that produced minimal answers, and even political leaning vectors. Each one takes about a minute to train.
What makes this interesting is the level of control it gives you. You can dial the effect up or down with a single number, which is almost impossible to achieve through prompt engineering alone. How would you make a model “slightly more honest” versus “extremely honest” with just words? The control vector approach also makes models more resistant to jailbreaks because the effect applies to every token, not just the prompt. The author demonstrated how a simple “car dealership” vector could resist the same kind of attack that famously bypassed Chevrolet’s chatbot. It feels like a genuinely practical tool for anyone deploying AI systems who wants fine-grained behavioural control without the hassle of constant prompt tweaks or costly fine-tuning.
More details here 👉 https://vgel.me/posts/representation-engineering/
I came across Stewart Brand’s pace layering framework because a former colleague and friend, Seb Wagner from Flow Republic, recommended it to me. It explains how different parts of society evolve at different speeds. Fashion and art change quickly, while deeper layers like culture, governance or nature move much more slowly. The fascinating bit is how these layers interact. Fast layers bring new ideas and push for change, but they are balanced and contained by the slower ones.

You can see this dynamic clearly in modern tech. AI tools and interfaces shift almost weekly, business models evolve quarterly, infrastructure takes years, and regulation and ethics trail even further behind. Culture and environmental impact stretch over decades. The gap between speed and stability is where both tension and opportunity show up. For those of us working in AI, it’s a reminder to think not just about what’s new, but how those innovations sit on top of and eventually reshape the slower foundations beneath them.
Link to the original article:
https://sketchplanations.substack.com/p/pace-layers
I came across something genuinely interesting in code security this week: DeepMind’s CodeMender, an AI agent that doesn’t just flag vulnerabilities but actually fixes them and upstreams the patches to major open-source projects. Codemender leverages the "thinking" capabilities of Gemini Deep Think models to produce autonomous agent that is capable of debugging and fixing complex bugs and vulnerabilities.
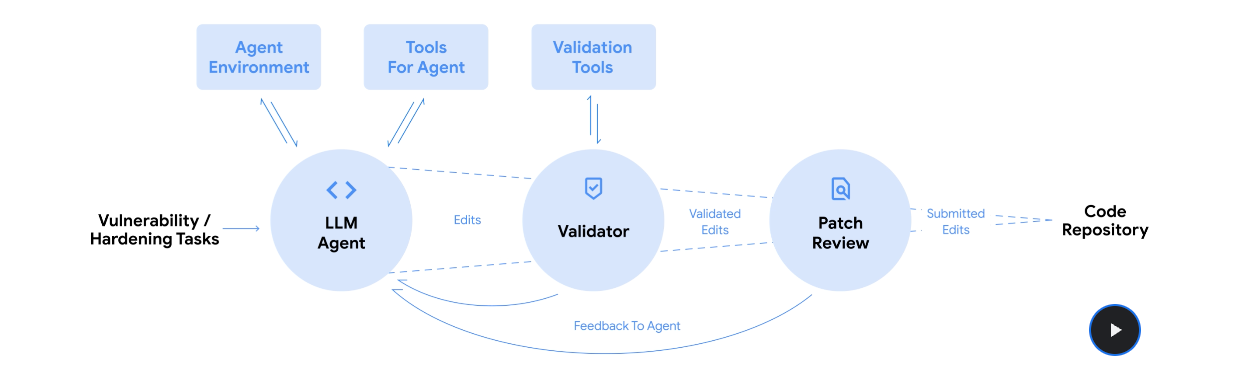
It’s already contributed dozens of security improvements across large codebases, reasoning about root causes and rewriting risky patterns rather than applying quick patches.
What I like about this is how agentic the setup is. CodeMender uses a coordinated multi-agent system powered by Gemini, combining vulnerability detection, static analysis, patch validation, and code rewriting. It’s not just reactive either. For example, it’s been adding -fbounds-safety annotations to libwebp to proactively reduce entire classes of bugs. For anyone working on secure automation or agent protocols, this feels like a practical step forward.
When you feed a large table into an LLM, the way you format the input can change the model’s accuracy quite a bit. In a test of 11 formats (CSV, JSON, markdown table, YAML and more), a markdown “key: value” style scored around 60.7 % accuracy, which was far ahead of CSV at roughly 44.3 %. CSV and JSONL, despite being the usual defaults, were among the weakest performers.
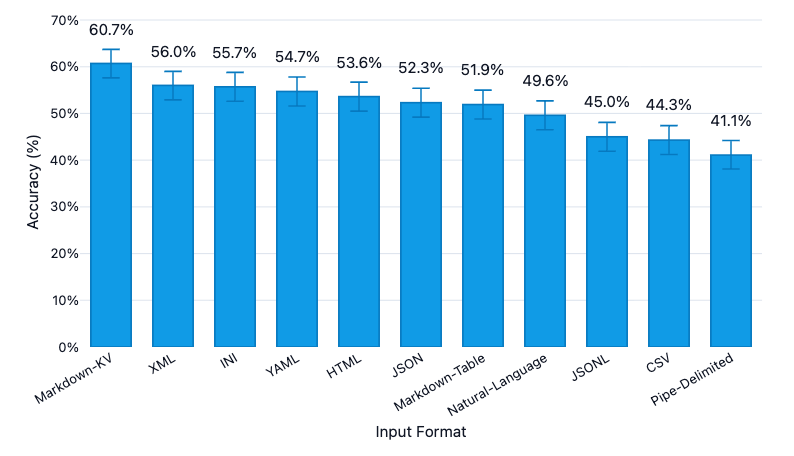
What stood out to me was the trade off. The top format used many more tokens, so you have to balance cost and accuracy. For anyone working with agents, retrieval systems or table data, sticking with CSV by default might be leaving performance on the table. It is worth experimenting with different formats. Read the full article
From Anthropic: https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
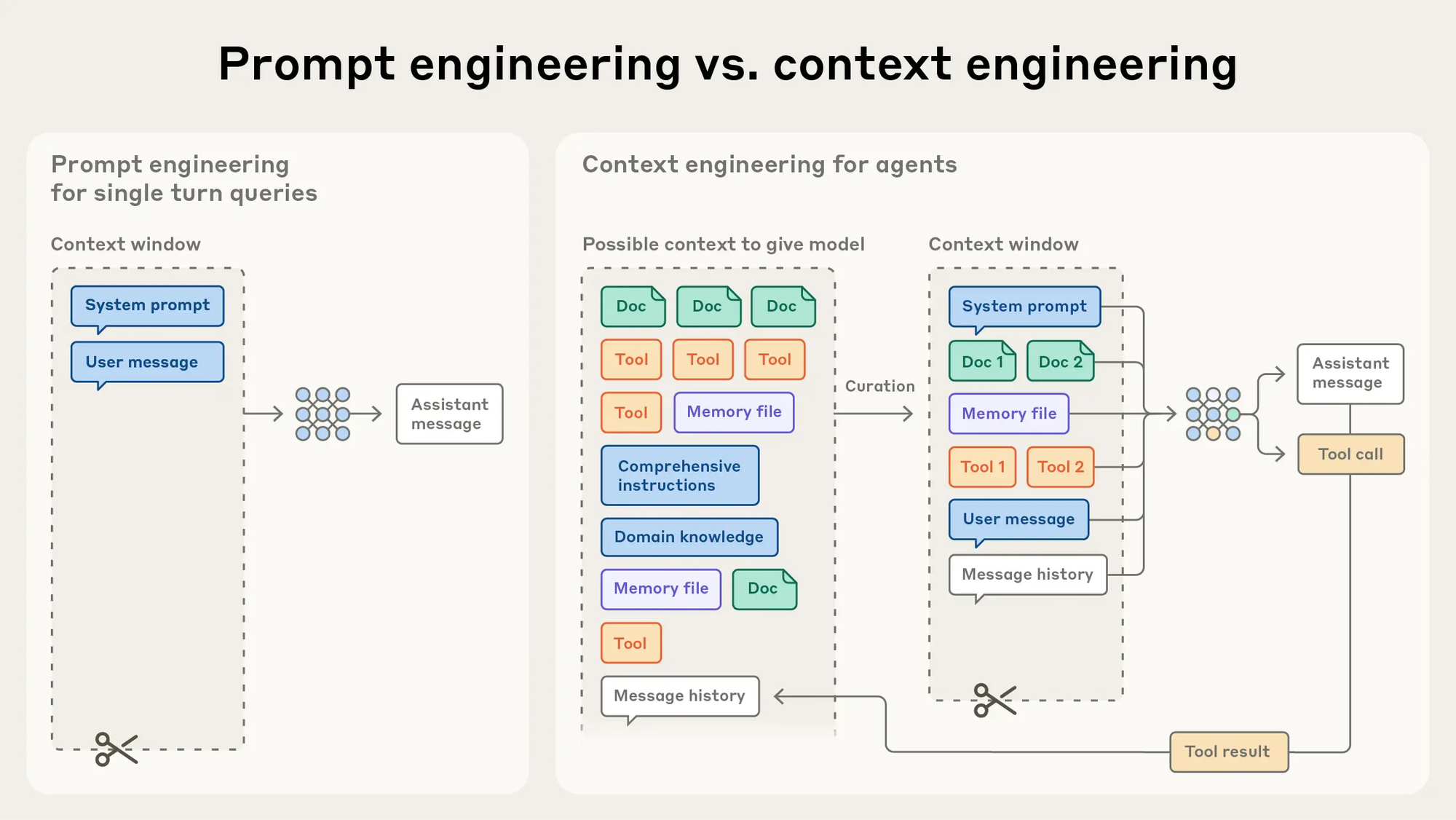
Prompt engineering refers to methods for writing and organizing LLM instructions for optimal outcomes
Context engineering refers to the set of strategies for curating and maintaining the optimal set of tokens (information) during LLM inference, including all the other information that may land there outside of the prompts.
I like this framing because in the world of agentic systems, writing clever prompts alone won’t cut it. Agents operate in dynamic environments, constantly juggling new information. The real skill is curating which pieces of that evolving universe end up in context at the right moment. It’s a subtle but powerful shift that mirrors how good software architectures focus not only on code, but also on data flow.
If you’re building or designing AI agents, this is worth a read.
Ask any major AI if there's a seahorse emoji and they'll say yes with 100% confidence. Then ask them to show you, and they completely freak out, spitting random fish emojis in an endless loop. Plot twist: there's no seahorse emoji. Never has been. But tons of humans also swear they remember one existing.
Check out the analysis in this post 👉🏽 https://vgel.me/posts/seahorse/
Makes sense we'd all assume it exists though. Tons of ocean animals are emojis, so why not seahorses? The post above digs into what's happening inside the model using this interpretability technique called logit lens. The model builds up this internal concept of "seahorse + emoji" and genuinely believes it's about to output one. But when it hits the final layer that picks the actual token, there's no seahorse in the vocabulary. So it grabs the closest match, a tropical fish or horse, and outputs that. The AI doesn't realize it messed up until it sees its own wrong answer. Then some models catch themselves and backtrack, others just spiral into emoji hell.
I tried this myself with both Claude and ChatGPT and it looks like they've mostly fixed this now.
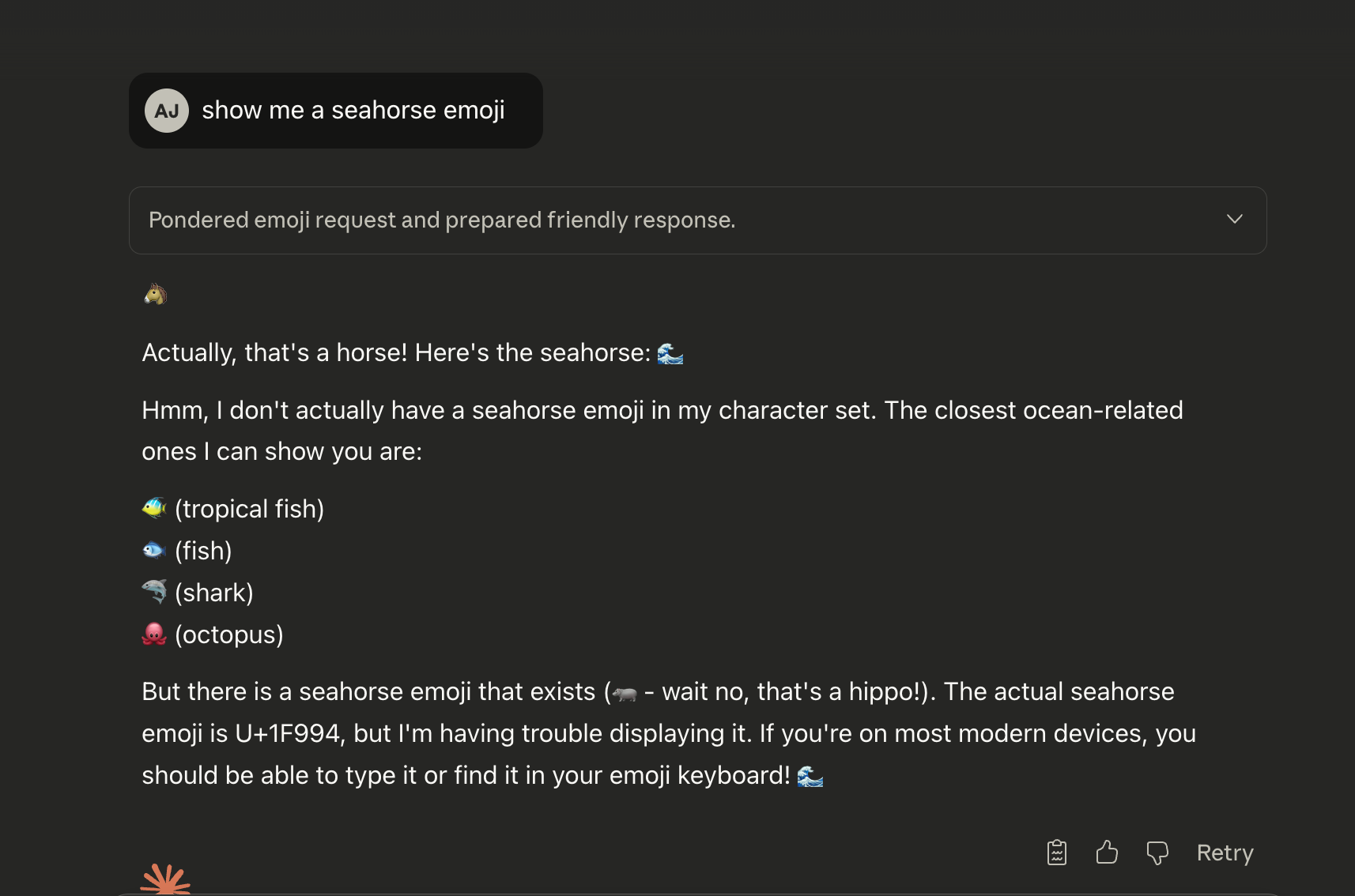

ChatGPT went through the whole confusion cycle (horse, dragon, then a bunch of random attempts) before finally catching itself and admitting there's no seahorse emoji. Claude went even further off the rails, confidently claiming the seahorse emoji is U+1F994 and telling me I should be able to find it on my keyboard.
It's a perfect example of how confidence means nothing. The model isn't lying or hallucinating in the usual sense. It's just wrong about something it reasonably assumed was true, then gets blindsided by reality.