The Frontier of Agent Memory: From Recall to Experience
Part 3 of a 3 part series post about AI Agent memory architecture.
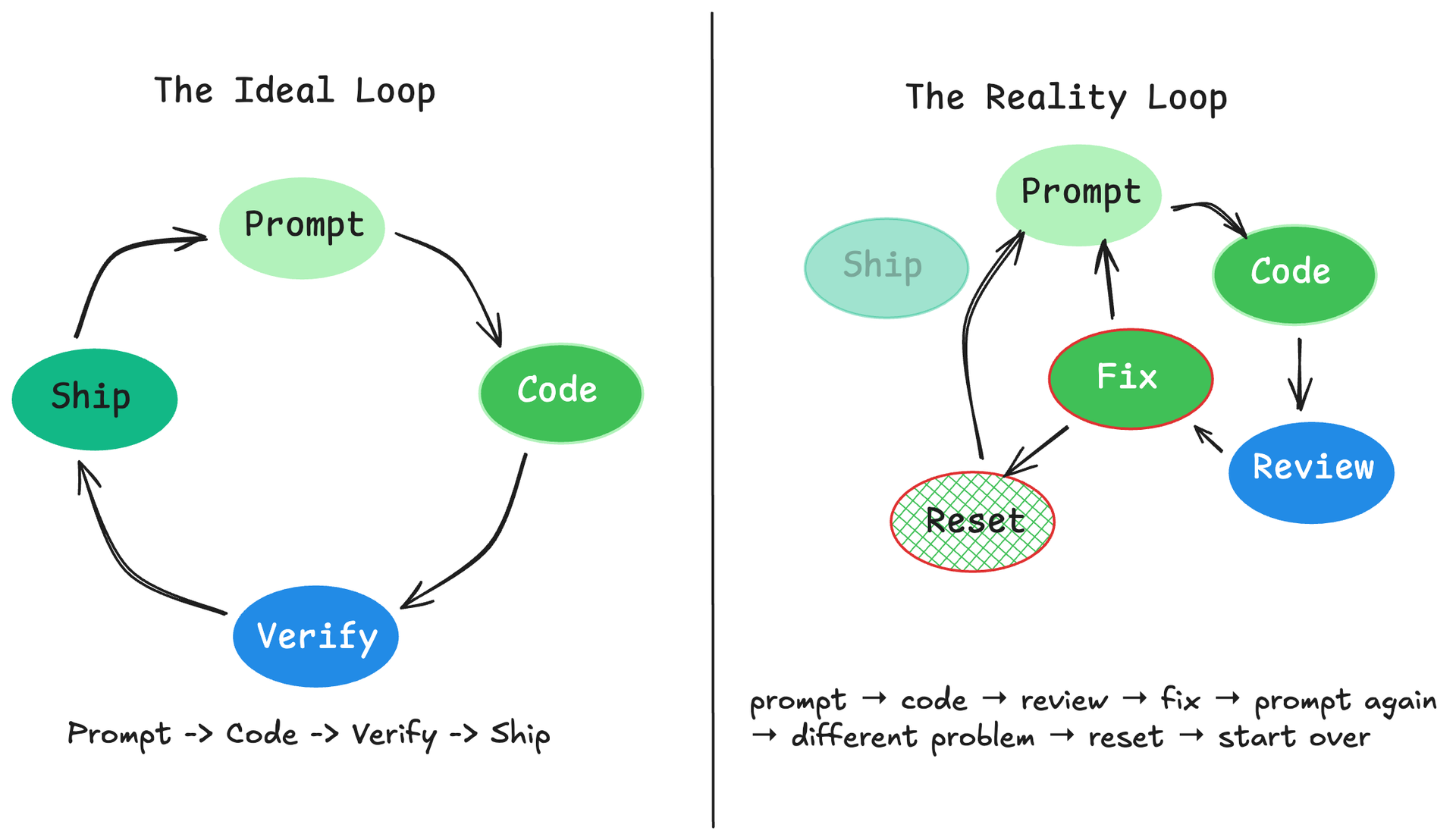
Welcome to Middle Loop Engineering
Where engineering rigour goes now that AI writes the code
Write Skills Like Workstations, Not Prompts
Claude Code skills work best when you treat them as workstations, not prompts: folders with scripts, gotchas, templates, and progressive disclosure that manage the agent's attention budget at runtime.
Ship Prompts Like Software: Regression Testing for LLMs
Because "it seemed fine when I tested it" is not a deployment strategy.
Part 4 of 4: Evaluation-Driven Development for LLM Systems
Four Ways to Grade an LLM (Without Going Broke)
Your evaluation technique should match the question you're asking, not your ambition.
Your Golden Dataset Is Worth More Than Your Prompts
Most teams spend weeks perfecting prompts and minutes on evaluation data. That's backwards.
Part 2 of 4: Evaluation-Driven Development for LLM Systems